S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation
- 1UC Berkeley,
- 2Waymo LLC,
- 3Cornell University,
- 4Georgia Institute of Technology
*Equal contribution
†Work done as interns in Waymo
CVPR 2025
-
 Paper
Paper
Abstract
The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches—which directly learn from sensor inputs to generate planning trajectories without human annotations—often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a Scalable Self-Supervised motion planning algorithm with Spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
Self-Supervised Learning Framework

Multi-task learning framework.
Self-supervised planning framework.
Enhancing MLLMs for End-to-End Motion Planning
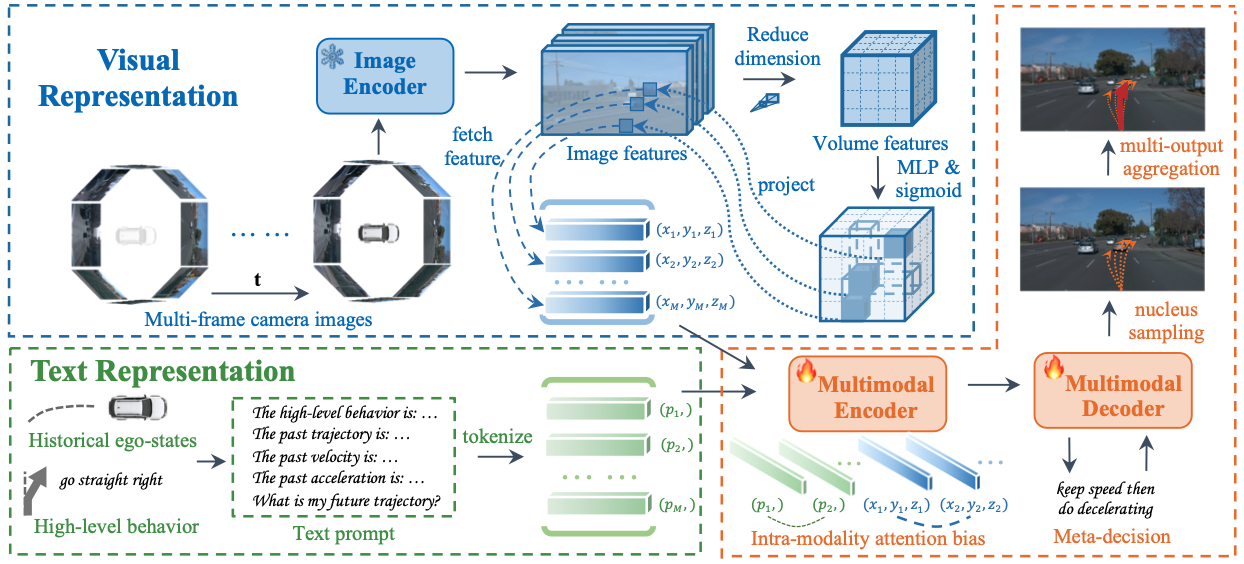
Top:
Overview of S4-Driver frameworks.
We enhance the PaLI model for motion planning by incorporating meta-decision, spatio-temporal visual representation, and multi-decoding aggregation.
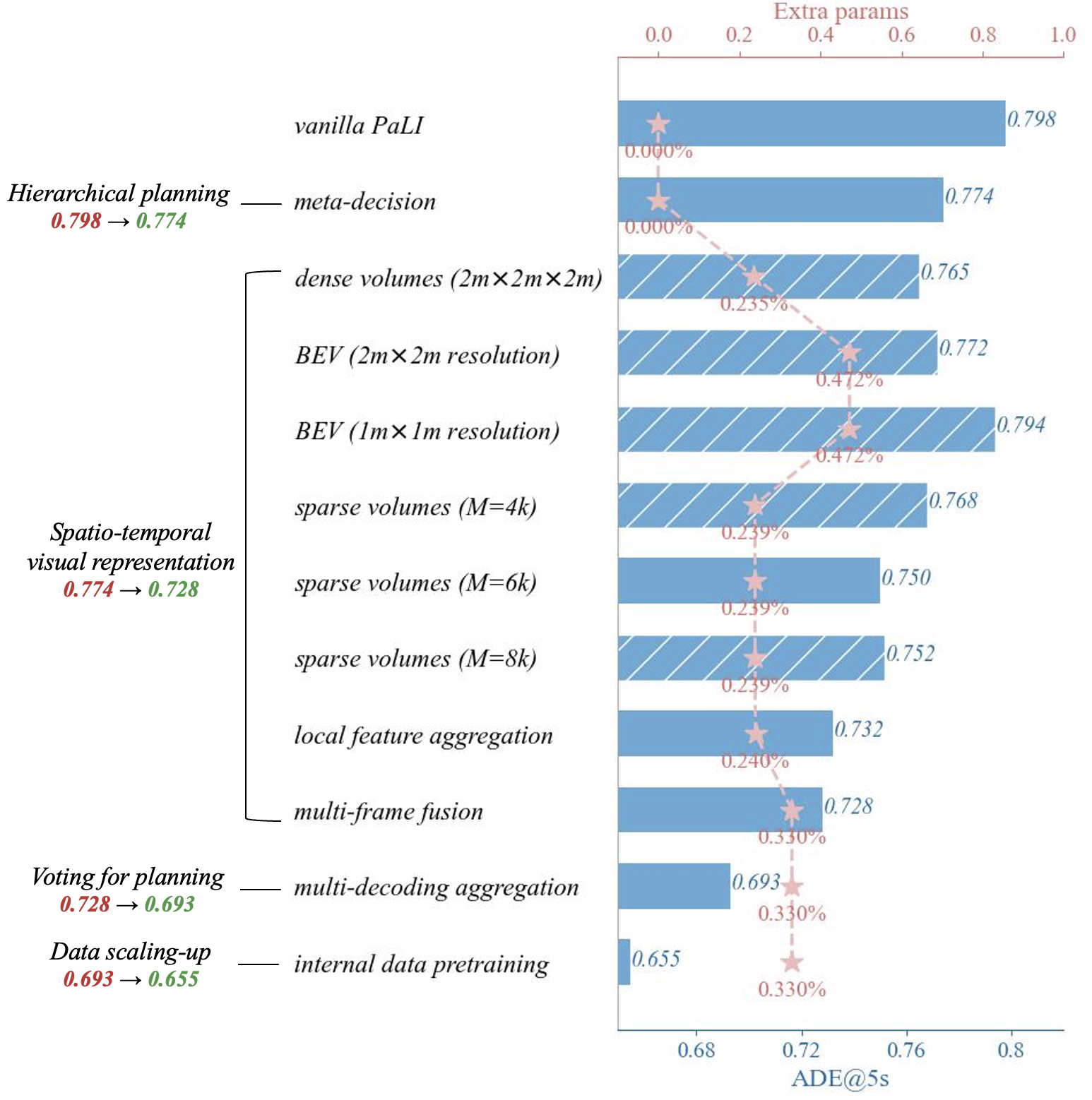
Left:
A roadmap for enhancing MLLM for planning.
We show the performance on Waymo Open Motion Dataset after including each module, while shadow items are not adopted in the subsequent steps.
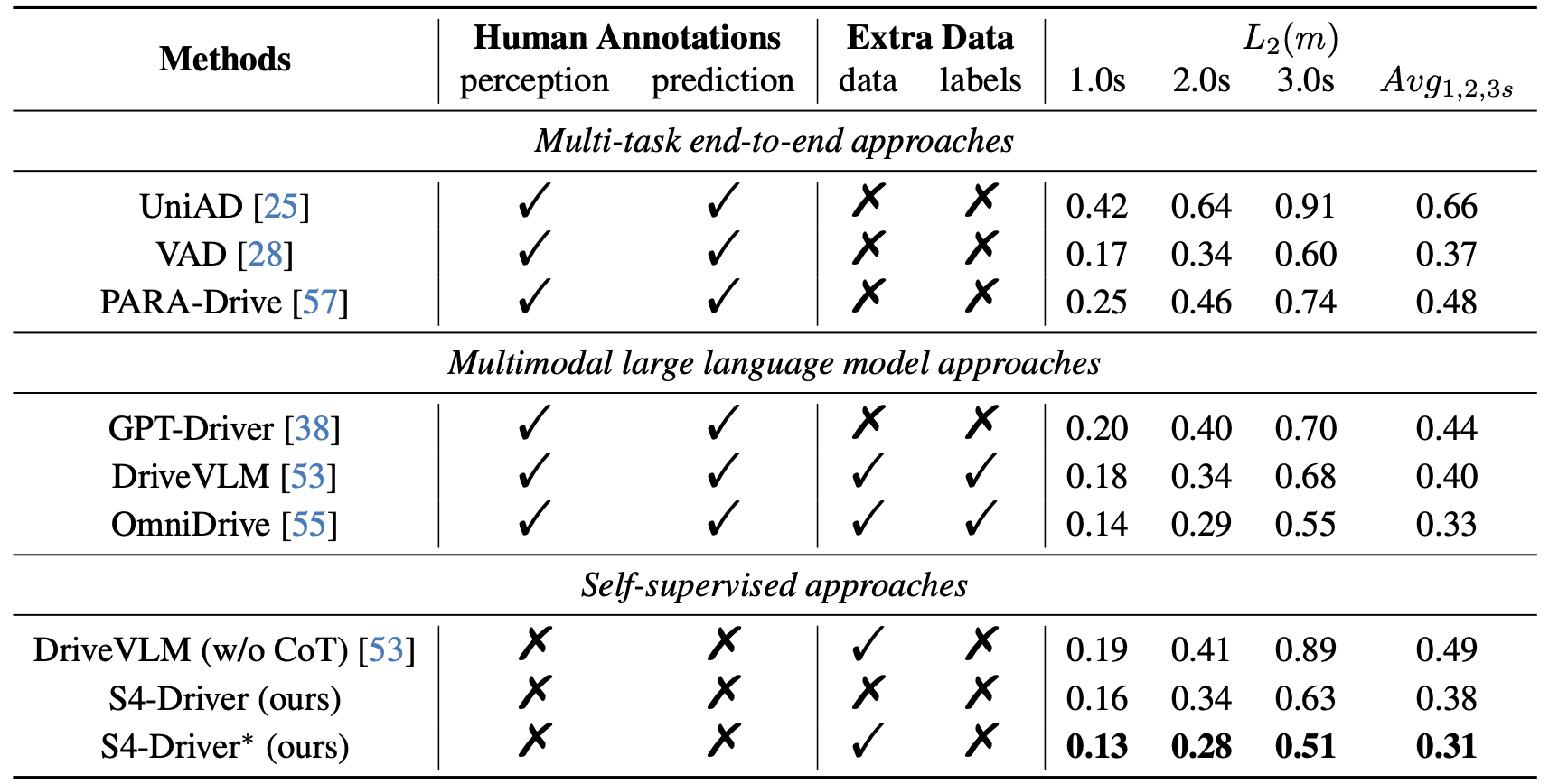
Results
Results on nuScenes Dataset.
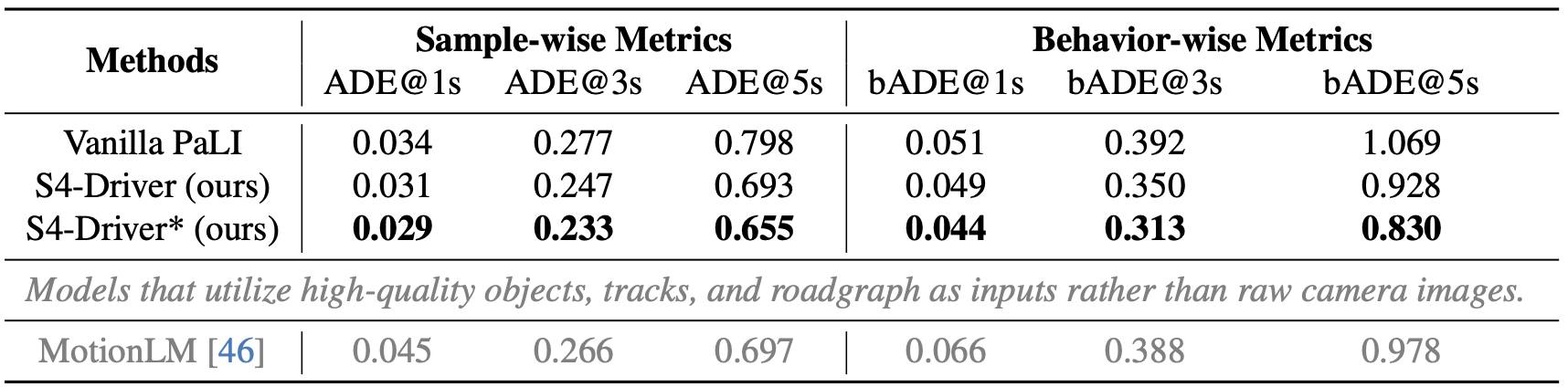
Results on Waymo Open Motion Dataset (with internal camera data).
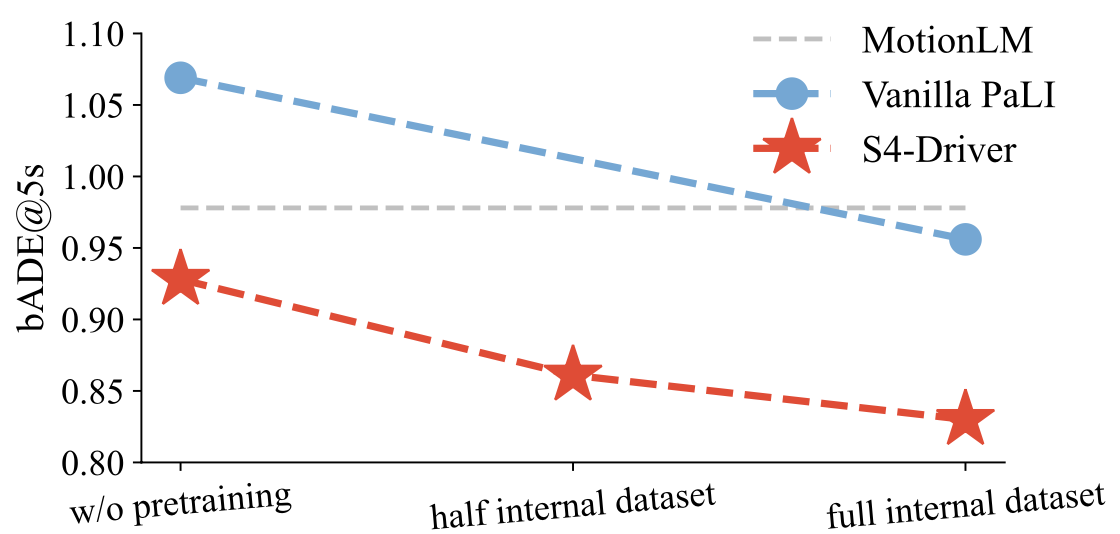
Data Scaling-up with Raw Driving Logs.
Visualizations
Extreme Weather.
Severe Shadow.


Reacting to Traffic Signals.


Bad Lighting Condition.


Turning.




Keeping the Lane.




Bibtex
@InProceedings{xie2025s4driver,
title={S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation},
author={Xie, Yichen and Xu, Runsheng and He, Tong and Hwang, Jyh-Jing and Luo, Katie Z and Ji, Jingwei and Lin, Hubert and Chen, Letian and Lu, Yiren and Leng, Zhaoqi and Anguelov, Dragomir and Tan, Mingxing},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}